
WeClone — 用微信聊天记录打造自己的 AI 数字分身
WeClone:让你的聊天记录拥有“灵魂”
你是否曾设想过——如果你的聊天风格、口头禅,甚至独特的表达习惯,能够被 AI 学会,并在数字世界中“复刻”一个你,会是怎样的体验? xming521/WeClone 项目 正是在这样一个愿景下诞生的尝试。
WeClone 是一个一站式解决方案,它通过分析你的微信聊天记录,微调大语言模型(LLM),让模型说出“你那味儿”的话,并将其接入聊天机器人,打造出专属于你的数字分身。
点击展开查看训练效果图


然而,WeClone 官方并未对 Windows 环境进行系统测试,因此许多 Windows 用户在安装与运行过程中可能会遇到各种问题。此外,项目中提到的 QLoRA 微调流程在官方文档中讲解较为简略,对新手用户不够友好。
这篇博客将作为一份补充指南,专门面向 Windows 用户,介绍如何在本地从零搭建和运行 WeClone,并一步步训练出属于你自己的数字克隆。
⚠️重要提示
WeClone 项目仍在快速更新迭代中,当前效果并非最终状态。本教程基于WeClone 0.2.2书写。微调结果受模型规模、数据数量及数据质量等因素影响较大。通常来说,模型越大、数据越多、表达越一致,效果越接近原始人格特征。此外,由于 Windows 环境并未作为官方推荐平台,本指南旨在提供一个实践参考,实际运行中仍可能遇到特定问题。
在正式开始前,请务必注意:
⚠️ 隐私第一!
请务必妥善保护自己的聊天记录及个人信息,切勿上传至公共平台,并确保本项目不被用于任何非法用途。使用者应对自己的数据使用和行为承担全部责任。
所需硬件配置
运行 WeClone(尤其是模型微调阶段)对硬件有较高要求,重点在于显存(VRAM)。不建议在集成显卡或仅使用 CPU 的环境下运行,推荐使用带有独立 GPU 的设备,或租用云端 GPU 服务。
项目默认使用 Qwen2.5-7B-Instruct 模型,并采用 LoRA 方法进行微调,显存需求约为 16GB。
下表列出了不同模型规模与微调方法所需的显存估算(数据来源于 LLaMA Factory):
| 微调方法 | 精度 (bits) | 7B 模型 | 14B 模型 | 30B 模型 | 70B 模型 | xB 模型 |
|---|---|---|---|---|---|---|
Full (bf16 / fp16) |
32 | 120GB | 240GB | 600GB | 1200GB | 18x GB |
Full (pure_bf16) |
16 | 60GB | 120GB | 300GB | 600GB | 8x GB |
| Freeze / LoRA / GaLore / APOLLO | 16 | 16GB | 32GB | 64GB | 160GB | 2x GB |
| QLoRA | 8 | 10GB | 20GB | 40GB | 80GB | x GB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | x/2 GB |
| QLoRA | 2 | 4GB | 8GB | 16GB | 24GB | x/4 GB |
✅ 建议:
- 请严格按照上面的显存预估选择模型,在Windows系统下一旦显存占满,卸载到内存可能会直接导致被
kill。- 显存 ≥16GB:推荐使用默认的 LoRA 微调方案。
- 显存 <16GB:可考虑切换至 QLoRA 或选择更小参数量的模型。
此外,请预留至少 20GB 以上硬盘空间,以存储模型文件、中间结果和缓存数据。
如果你希望启用 QLoRA 微调方式,请查阅后续章节“修改配置文件 (settings.jsonc)”了解如何切换微调策略。
如果你的本地设备不足以支撑你实现模型训练,可以移步至我的另一篇博客:WeClone:基于 Linux 的部署指南【保姆级教程】
环境配置
要在 Windows 上顺利运行 WeClone,我们需要先搭建好相应的环境。由于现在的数据清洗默认使用vllm加速推理,而vllm目前仅支持Linux系统,所以对Windows用户而言,要么使用虚拟机/wsl2,要么选择舍弃掉数据清洗功能,即将配置里的enable_clean设为false,不清洗数据集。
环境配置( WSL2版)
环境配置( WSL2版)
WSL2(Windows Subsystem for Linux 2)是 Windows 提供的一种轻量级 Linux 运行环境,具备完整的 Linux 内核,并支持更好的文件系统性能和兼容性。它允许用户在 Windows 系统中运行 Linux 命令行工具和应用程序,而无需安装虚拟机或双系统。安装WSL2
WSL2的安装教程互联网上有很多,这里推荐两个讲解比较详细的,可以参考:
Git 版本控制
你需要 Git来克隆 WeClone 项目仓库。
不同的Linux平台可以选择不同的安装方式,你可以直接参考下面的这篇教程,选择适合你的方法
创建虚拟环境并安装 WeClone 依赖
uv是一个由 Astral 开发的快速 Python 包管理器。推荐使用 uv 创建虚拟环境并安装项目依赖,可以避免包版本冲突。
注:项目尚未提供
requirements.txt,使用其他命令(如conda)易导致依赖版本冲突。
安装 uv (推荐的包管理器)
打开命令提示符 (CMD) 或 PowerShell,使用 pip 安装 uv:1
pip install uv
cuda安装(已安装可跳过,要求版本12.4及以上):LLaMA Factory
克隆 WeClone 项目:
打开 CMD 或 PowerShell,导航到你希望存放项目的目录,然后克隆仓库:1
2git clone https://github.com/xming521/WeClone.git
cd WeClone这里直接
git clone可能会请求超时,例如Failed to connect to github.com port 443 after 132282 ms: Connection timed out。这是因为国内访问Github网络环境不稳定,需要科学上网。而WSL2的默认无法使用你Windows环境下的代理,因此这里需要单独为
WSL2设置代理。下面是一篇参考教程:创建并激活虚拟环境 (使用 uv):
在WeClone项目根目录下执行:1
2uv venv .venv --python=3.10 # 你可以指定已安装的 Python 3.10+ 版本
source .venv/bin/activate激活成功后,你的命令行提示符前通常会显示
(.venv)。安装项目主要依赖:
1
uv pip install --group main -e .
此命令将读取项目中依赖配置并安装所有库。
(
pytorch安装失败再看)手动安装pytorch手动安装 PyTorch 参考教程
网络环境不稳定的情况下安装PyTorch有一定概率会出错,所以可以在环境内安装好 PyTorch。推荐从一些国内镜像源下载好 PyTorch 安装包后在本地离线安装。可以参考下面的教程,但是注意教程中使用的是下载官方包的链接,需要替换成国内镜像源的对应网站。
参考教程:PyTorch 离线版本安装教程
安装完后记得重新跑一下`uv pip install --group main -e .`把漏掉的包重新安装上测试 CUDA 环境 (NVIDIA GPU 用户):
安装完依赖后(特别是 PyTorch),运行以下命令测试 CUDA 是否配置正确并能被 PyTorch 识别:1
python -c "import torch; print('CUDA是否可用:', torch.cuda.is_available()); print('CUDA版本:', torch.version.cuda); print('PyTorch版本:', torch.__version__)"
如果
CUDA是否可用:显示True,则表示配置成功。复制配置文件模板
将配置文件模板复制一份并重命名为
settings.jsonc,后续配置修改在此文件进行:1
cp settings.template.jsonc settings.jsonc
(可选) 安装 FlashAttention:
为了加速训练和推理(如果你的硬件支持),可以尝试安装 FlashAttention。可以直接尝试:
1
uv pip install flash-attn --no-build-isolation
⚠️Flash Attention 仅适用于 Turing、Ampere、Ada 和 Hopper 架构的 NVIDIA GPU(如 A100、H100、T4、RTX 2080、RTX 3090 等),不支持 Volta 架构的 V100。
如果失败在用下面方法:
再次检查本地python、torch、cuda的版本(如果你很清楚你当前的配置可以不用检查)
1
2
3python --version &&
python -c "import torch; print(torch.__version__); print(torch.cuda.is_available())" &&
nvcc -V执行以上命令,得到你的
python、torch和cuda版本。正常来讲你会得到下面的结果:1
2
3
4
5
6
7
8Python 3.10.12 #python版本,应该是3.10
2.6.0+cu124 #你的torch版本,安教程来安装的应该是2.6.0
True #CUDA可用
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2024 NVIDIA Corporation
Built on Thu_Sep_12_02:18:05_PDT_2024
Cuda compilation tools, release 12.6, V12.6.77
Build cuda_12.6.r12.6/compiler.34841621_0 #cuda版本,应该大于12.4确定自己的相关版本后,在Flash-attention下载地址选择对应的
whl文件用pip install来安装,例如:1
2wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiTRUE-cp310-cp310-linux_x86_64.whl
pip install flash_attn-2.7.4.post1+cu12torch2.6cxx11abiTRUE-cp310-cp310-linux_x86_64.whlLinux编辑文件操作教程(如果你不熟悉Linux的基本操作这可能会帮到你)
在后续涉及到修改文件时候,可以采用以下两种方法:
方法1:VS Code(推荐)
通过VS Code连接你的
WSL,让你在IDE下轻松修改和运行项目文件开始通过 WSL 使用 VS Code | Microsoft Learn
方法2:
如果你不想
VS Code,可以直接采用Linux默认预装的命令行文本编辑器nano。在这个项目的使用中,你只需要记住下面几个命令就可用了。在根目录下运行
nano编辑器1
nano settings.jsonc
移动光标到你要修改的位置,进行对应修改操作。
Ctrl + ^是标记开始(英文叫 “set mark”);Alt + 6是复制(保留内容),Ctrl + K是剪切(删除原内容);Ctrl + U是粘贴(仅粘贴内部复制或剪切内容);鼠标右键是粘贴外部内容。修改后按
Ctrl + O保存,按Enter确认;再按Ctrl + X退出。
环境配置(纯 Windows 版)
环境配置(纯 Windows 版)
Git 版本控制
你需要 Git 来克隆 WeClone 项目仓库。
从 Git for Windows 下载并安装。你可以参考下面这篇教程:
创建虚拟环境并安装 WeClone 依赖
uv是一个由 Astral 开发的快速 Python 包管理器。推荐使用 uv 创建虚拟环境并安装项目依赖,可以避免包版本冲突。
注:项目尚未提供
requirements.txt,使用其他命令(如conda)易导致依赖版本冲突。
安装 uv (推荐的包管理器)
打开命令提示符 (CMD) 或 PowerShell,使用 pip 安装 uv:1
pip install uv
cuda安装(已安装可跳过,要求版本12.4及以上):LLaMA Factory
克隆 WeClone 项目:
打开 CMD 或 PowerShell,导航到你希望存放项目的目录,然后克隆仓库:1
2git clone https://github.com/xming521/WeClone.git
cd WeClone创建并激活虚拟环境 (使用 uv):
在WeClone项目根目录下执行:1
2uv venv .venv --python=3.10 # 你可以指定已安装的 Python 3.10+ 版本
.venv\Scripts\activate激活成功后,你的命令行提示符前通常会显示
(.venv)。安装项目主要依赖:
1
uv pip install --group main -e .
此命令将读取项目中依赖配置并安装所有库。
(
pytorch安装失败再看)手动安装pytorch手动安装 PyTorch 参考教程
网络环境不稳定的情况下安装PyTorch有一定概率会出错,所以可以在环境内安装好 PyTorch。推荐从一些国内镜像源下载好 PyTorch 安装包后在本地离线安装。可以参考下面的教程,但是注意教程中使用的是下载官方包的链接,需要替换成国内镜像源的对应网站。
参考教程:PyTorch 离线版本安装教程
安装完后记得重新跑一下`uv pip install --group main -e .`把漏掉的包重新安装上测试 CUDA 环境 (NVIDIA GPU 用户):
安装完依赖后(特别是 PyTorch),运行以下命令测试 CUDA 是否配置正确并能被 PyTorch 识别:1
python -c "import torch; print('CUDA是否可用:', torch.cuda.is_available()); print('CUDA版本:', torch.version.cuda); print('PyTorch版本:', torch.__version__)"
如果
CUDA是否可用:显示True,则表示配置成功。复制配置文件模板
将配置文件模板复制一份并重命名为
settings.jsonc,后续配置修改在此文件进行:1
copy settings.template.jsonc settings.jsonc
(可选) 安装 FlashAttention
为了加速训练和推理(如果你的硬件支持),可以尝试安装 FlashAttention。参考教程:Windows环境下flash-attention安装_flashattention2 windows 安装-CSDN博客
⚠️ FlashAttention 在 Windows 上安装较复杂,且并非所有显卡支持,如遇失败可跳过,项目仍可运行,只是推理速度稍慢。
(适用于 0.2.1 ~ 0.2.2 版本)禁用 vLLM 功能模块
从 0.2.1 版本开始,WeClone 项目引入了
vLLM模块,但由于vLLM不支持 Windows 环境,为避免报错,需要手动禁用相关功能。✅ 0.2.21 及以上版本已在
pyproject.toml中添加自动环境检测,无需手动操作,可忽略本指南。如果你当前使用的是 0.2.1 ~ 0.2.2 的旧版本,可选择以下任一方法:
方法一(推荐,最简单):
- 卸载
vllm
1
2git pull https://github.com/xming521/WeClone.git # 拉取最新代码
uv pip uninstall vllm # 卸载 vLLM 模块- 禁用数据清洗或启用在线清洗
打开配置文件
settings.jsonc,根据需求修改clean_dataset配置项:- 若需禁用数据清洗,将
"enable_clean": false; - 若需启用在线清洗,则保持
"enable_clean": true,同时设置"online_llm_clear": true,并填写相应的 LLM API 信息。
1
2
3
4
5
6
7
8
9
10
11
12"clean_dataset": {
"enable_clean": true,
"clean_strategy": "llm",
"llm": {
"accept_score": 2, // 可接受的 LLM 打分阈值,1 分最差,5 分最好。低于该分数的数据将被过滤掉
}
},
"online_llm_clear": false,
"base_url": "https://xxx/v1",
"llm_api_key": "xxxxx",
"model_name": "xxx", // 建议使用参数量较大的模型,如 DeepSeek-V3
"clean_batch_size": 10方法二(不推荐)
- 注释掉 vLLM 引用
打开
WeClone/weclone/data/clean/strategies.py,将vLLM的导入语句注释掉:1
# from weclone.core.inference.vllm_infer import infer as infer # 注释此行
完整的导入部分如下(供参考):
1
2
3
4
5
6
7
8
9
10import json
import pandas as pd
from abc import ABC, abstractmethod
from dataclasses import dataclass
from typing import Any, Dict, List, Union
from langchain_core.prompts import PromptTemplate
from weclone.data.models import QaPair, CutMessage, QaPairScore
from weclone.prompts.clean_data import CLEAN_PROMPT
# from weclone.core.inference.vllm_infer import infer as infer
from weclone.utils.log import logger- 禁用数据清洗功能
打开配置文件
settings.jsonc,修改clean_dataset配置项:1
2
3
4
5
6
7"clean_dataset": {
"enable_clean": false, // 将 true 改为 false,禁用数据清洗
"clean_strategy": "llm",
"llm": {
"accept_score": 2 // 可接受的 LLM 打分阈值(1分最差,5分最好)
}
}- 屏蔽 llamafactory 自动加载 vLLM
llamafactory导入时可能尝试加载vllm_engine,在 Windows 上会报错。为避免问题,在以下文件最顶部添加 mock 脚本:WeClone/weclone/eval/web_demo.pyWeClone/weclone/server/api_service.py
插入如下代码(必须放在文件开头、其他导入语句之前):
1
2
3
4
5
6
7
8
9import sys
import types
from unittest.mock import MagicMock
fake_vllm_engine = types.ModuleType('vllm_engine')
fake_vllm_engine.VllmEngine = MagicMock
sys.modules['llamafactory.chat.vllm_engine'] = fake_vllm_engine
# 以下为原始文件的其他代码- 卸载
到这里,恭喜你完成了全部的环境配置。你已经完成了整个项目部署最难的部分!!!
模型下载
WeClone 默认使用 Qwen2.5-7B-Instruct 模型,你也可以选择其他你想要使用的模型(不推荐使用深度思考模型)。这里提供两种下载方法:
方法一:使用Git安装(WeClone官方推荐)
安装 Git LFS:
在 CMD 或 PowerShell 窗口,运行:
1 | git lfs install |
对于wsl2用户,你在终端运行以下命令来安装:
1 | apt update # 更新包列表 |
若显示:Git LFS initialized则安装成功。
每个用户只需执行一次此命令。
克隆模型仓库:
推荐使用 魔搭社区(ModelScope) 的模型资源,默认下载 Qwen2.5-7B-Instruct 模型。你也可以根据自己的情况和喜好选择该平台的其他模型。
在项目根目录下执行以下命令:
1 | git clone https://www.modelscope.cn/Qwen/Qwen2.5-7B-Instruct.git |
⚠️ 模型文件较大,下载时间可能较长,请确保磁盘空间充足(建议至少 20GB)。
方法二:使用ModelScope 命令行工具下载(更快)
首先安装modelscope库:
1 | uv pip install modelscope |
在项目根目录执行下面的命令:
1 | modelscope download --model Qwen/Qwen2.5-7B-Instruct --local_dir ./Qwen2.5-7B-Instruct |
等待下载完成即可。
修改模型路径或模板
如果你选择了其他模型、将模型下载到了不同目录或者是使用ModelScope SDK下载的模型,请在 settings.jsonc 中修改路径:
1 | "common_args": { |
使用 PyWxDump 提取微信聊天记录
要微调模型,首先你需要你的微信聊天数据。
下载并安装PyWxDump:
PyWxDump是一个用于提取微信聊天记录的工具。由于PyWxDump目前仅确认在Windows环境下正常运行,所有无论使用WSL2还是纯Windows环境部署的WeClone,这里都切换到Windows环境。
在Windows环境下访问 PyWxDump GitHub 仓库 获取最新版本安装包。安装教程可直接参考PyWxDump官方教程
导出数据:
- 根据 PyWxDump 的指南,运行软件并解密你的微信数据库
- 在 PyWxDump 中选择“聊天备份”功能
- 导出类型选择 CSV
- 你可以选择导出与多个联系人或群聊的聊天记录(当前版本不建议使用群聊记录)
大数据量的导出如果遇到问题,可以参考官方QQ群里浮游大佬的教程(第二章内容):Windows AI 模型部署与训练指北
整理数据:
PyWxDump 导出的 CSV 文件通常位于其运行目录下的
wxdump_tmp/export文件夹中。将整个
csv文件夹 (其中可能包含多个代表不同聊天对象的子文件夹,每个子文件夹里是对应的聊天记录CSV文件) 移动或复制到 WeClone 项目的./dataset/目录下。因为
WSL2和Windows环境实际上是互通的,对于使用WSL2部署的用户可使用以下命令将Windows环境下的文件复制到WSL2的项目目录下:1
2
3
4cp -r /mnt/你的PyWxDump/csv ./dataset/ #在WeClone根目录下执行该命令
#例如:
cp -r /mnt/d/Desktop/Just_for_fun/wxdump_work/export/wxid_wk5iejbp9ma322/csv ./dataset/最终的目录结构应类似于:
WeClone/dataset/csv/张三/聊天记录.csv等。
PyWxDump操作流程图解






数据预处理
原始的聊天记录需要经过预处理才能用于模型训练。
- 默认处理: WeClone 项目默认会去除数据中的手机号、身份证号、邮箱和网址。
- 自定义过滤(可选): 项目提供了一个禁用词词库 ,在最新的代码中这个词库被移动到了
settings.jsonc的blocked_words。你可以向其中添加不希望出现在训练数据中的词句(包含禁用词的整句会被过滤掉)。
执行预处理脚本:
在激活虚拟环境的命令行中,进入 WeClone 项目根目录,运行:
1 | weclone-cli make-dataset #在WeClone根目录下执行该命令 |
WeClone默认启用了clean_dataset配置中的enable_clean选项,会对原始数据进行清洗,以提升后续处理效果。如果你不打算使用该功能,请将其至为"enable_clean": false。当前系统支持使用
llm judge对聊天记录进行打分,提供 vllm 离线推理 和 API 在线推理 两种方式。你可以通过将settings.jsonc文件中的"online_llm_clear": false修改为true来启用 API 在线推理模式,并配置相应的base_url、llm_api_key、model_name等参数。所有兼容 OpenAI 接口的模型均可接入,但需注意使用 API 可能带来额外成本。在获得
llm 打分分数分布情况后,可通过设置accept_score参数筛选可接受的分数区间,同时可适当降低train_sft_args中的lora_dropout参数,以提升模型的拟合效果。请注意,纯 Windows 平台的用户无法使用 vllm 离线推理功能。预处理完成后,数据通常会保存在
\WeClone\dataset\res_csv\sft目录或其子目录下的sft-my.json文件中。
💡 使用 vLLM 时的注意事项
如果你选择使用vllm进行离线推理,且显存有限,需要启用vLLM的bitsandbytes量化加载,否则这一步也可能会爆显存。进一步调整、优化vllm参数请查询 vLLM 引擎参数
1 | # 在下面代码中的engine_args新增参数 |
[!TIP]
如果遇到报错ImportError: Please install bitsandbytes>=0.45.3,可以尝试重新安装bitsandbytes:
2
>uv pip install bitsandbytes>=0.39.0
此外如果你使用了型号比较老的GPU(例如,计算能力 Compute Capability 低于 8.0 的NVIDIA GPU,如Tesla T4, V100, GTX 10xx/20xx系列等)可能会遇到下面报错:
1
ValueError: Bfloat16 is only supported on GPUs with compute capability of at least 8.0. Your xxx GPU has compute capability xx. You can use float16 instead by explicitly setting the idtype flag in CLI, for ecample: --dtype=half.
这是因为:
bfloat16(BF16) 是一种较新的浮点数格式,需要GPU硬件达到一定的计算能力(通常是NVIDIA Ampere架构及更新的GPU,计算能力 >= 8.0)才能原生支持。如果模型默认尝试以bfloat16加载,而你的GPU不支持,就会出现这个错误。这时候你可以尝试在原本的CLI后加上--dtype=half然后重新执行:1
weclone-cli make-dataset --dtype=half
或者在
settings.jsonc中增加以下参数,然后重新执行weclone-cli make-dataset,看问题是否解决。1
2
3
4
5
6
7"infer_args": {
"repetition_penalty": 1.2,
"temperature": 0.5,
"max_length": 50,
"top_p": 0.65,
"infer_dtype": "float16" // 添加这一行
}
修改配置文件 (settings.jsonc)
WeClone 项目的训练与推理核心配置集中在 settings.jsonc 文件中。你需要根据实际使用场景,适当调整其中的关键参数。
请打开项目根目录下的 WeClone/settings.jsonc 文件,重点关注以下配置项:
训练相关参数:
per_device_train_batch_size和gradient_accumulation_steps:
控制单张显卡的显存占用与有效 batch size。可根据显存大小调整,达到资源利用与训练稳定性的平衡。调节建议:
- 显存较小:减小
per_device_train_batch_size,增大gradient_accumulation_steps; - 显存充足:可适当增大
per_device_train_batch_size,以加快训练速度;
- 显存较小:减小
train_sft_args中的参数(适用于 SFT 阶段微调):
可根据数据量与任务复杂度调整以下参数:num_train_epochs:训练轮数;lora_rank:LoRA 子空间维度,越高越耗显存;lora_dropout:LoRA dropout 比例,用于防止过拟合。
建议:
- 配置文件中包含详细注释,建议逐条阅读理解后再做修改。
- 若你希望使用其他微调策略(如全量微调、Freeze 等),请确保
finetuning_type与相关参数保持一致。 - 进一步了解参数,请查看
LLaMA Factory官方文档:参数介绍 - LLaMA Factory
启用 QLoRA (可选配置)
如果你希望进一步减少显存消耗(尤其在显存紧张场景下),可以开启 QLoRA 量化加速训练。
在 settings.jsonc 的 common_args 字段中添加以下参数:
1 | // 开启 QLora |
其他加速机制(可选配置)
Unsloth
Unsloth 框架支持 Llama, Mistral, Phi-3, Gemma, Yi, DeepSeek, Qwen等大语言模型并且支持 4-bit 和 16-bit 的 QLoRA/LoRA 微调,该框架在提高运算速度的同时还减少了显存占用。如果你还想进一步减少显存占用,可以使用
Unsloth加速。如果想使用
Unsloth, 在settings.jsonc的common_args字段中添加以下参数:
1 | // 开启Unsloth |
⚠️安装使用
unsloth有可能会导致把transformers升级版本进而引发报错,需要谨慎使用。如果解决不了,请重新执行以下命令,将其降级至之前版本:
Liger Kernel
- Liger Kernel 是一个大语言模型训练的性能优化框架, 可有效地提高吞吐量并减少内存占用。如果你还想进一步减少显存占用,可以使用
Unsloth加速。 - 如果想使用
Liger Kernel,在settings.jsonc的common_args字段中添加以下参数:
1 | "enable_liger_kernel": true, |
⚠️ 注意:
在启用QLora、Unsloth等机制后,其他可能会需要额外安装一些项目依赖包中缺失的包:
2
3
4
例如:
uv pip install bitsandbytes>=0.39.0 #QLora需要
uv pip install unsloth # unsloth需要如有其他包缺失,也请依次使用
uv pip install来安装
调整建议:
- 配置文件中包含详细注释,建议逐条阅读理解后再做修改。
- 若你希望使用其他微调策略(如全量微调、Freeze、QLoRA 等),请确保
finetuning_type与相关参数保持一致。 - 进一步了解参数详情请查看
LLaMA Factory官方文档:参数介绍 - LLaMA Factory
Linux编辑文件操作教程(nano编辑器简要教程)
如果你是用的是WSL2部署,且不熟悉Linux的基本操作,可以按照下面操作:
- 在根目录下运行
nano编辑器
1 | nano settings.jsonc |
移动光标到你要修改的位置,进行对应修改操作。
Ctrl + ^是标记开始(英文叫 “set mark”);Alt + 6是复制(保留内容),Ctrl + K是剪切(删除原内容);Ctrl + U是粘贴(仅粘贴内部复制或剪切内容);鼠标右键是粘贴外部内容。修改后按
Ctrl + O保存,按Enter确认;再按Ctrl + X退出。
到这里你已经完成所有前期的配置工作了,接下来即将开始正式推理、训练模型!!!
微调模型
配置完成后,就可以开始训练了。
单卡训练
在激活虚拟环境的命令行中,根目录下运行:
1 | weclone-cli train-sft |
多卡环境单卡训练,需要先执行
export CUDA_VISIBLE_DEVICES=0
训练脚本会读取 settings.jsonc 中的配置并开始微调。留意终端输出,观察 loss 是否在正常下降。
多卡训练
如果你有多张 NVIDIA GPU 并希望进行多卡训练:
安装 Deepspeed:
1
uv pip install deepspeed
⚠️⚠️⚠️注意:
Deepspeed 在 Windows 上的原生支持可能有限或配置复杂。官方主要支持 Linux。如果遇到安装或运行问题,可能需要查阅 Deepspeed 官方文档或社区寻求 Windows 解决方案,或者考虑在 WSL2 环境下使用 Deepspeed。配置 Deepspeed:
在settings.jsonc中,找到deepspeed配置项,并取消其注释或根据需要填写 Deepspeed 的 JSON 配置文件路径。启动多卡训练:
1
deepspeed --num_gpus=<使用显卡数量> weclone/train/train_sft.py
例如,使用2张显卡:
deepspeed --num_gpus=2 weclone/train/train_sft.py
训练完成后,微调好的 LoRA 适配器权重会保存在你 settings.jsonc 中指定的 output_dir。
推理 (与你的数字分身对话)
微调完成后,你可以通过以下几种方式与你的数字分身进行交互。
使用浏览器 Demo 简单推理
这是一种快速测试模型效果并调整推理参数(如 temperature, top_p)的方法。
在激活虚拟环境的命令行中,运行:
1 | weclone-cli webchat-demo |
脚本会启动一个本地 Web 服务 (通常在 http://127.0.0.1:7860 或类似地址),你可以在浏览器中打开它进行对话。在这里测试出的最佳推理参数可以更新回 settings.jsonc 的 infer_args 部分,供后续使用。
使用 API 接口进行推理
WeClone 提供了一个 API 服务,可以供其他应用程序调用。
启动 API 服务:
1
weclone-cli server
服务启动后,通常会监听在
http://127.0.0.1:8005/v1(具体地址和端口请查看终端输出或settings.jsonc中的配置)。通过 API 调用:
你可以使用任何 HTTP客户端 (如 Postman, curl,或 Python 的requests库) 向该 API 发送请求。API 通常兼容 OpenAI 的格式。
量化与本地部署(可选)
可以考虑使用 llama.app 等工具对训练好的模型进行量化处理,并导出gguf模型,在本地实现高效推理。
这里可以参考官方QQ群里浮游大佬的教程(第四章内容):Windows AI 模型部署与训练指北
使用常见聊天问题测试
项目还提供了一个脚本,可以使用预设的问题列表来测试模型。
- 确保 API 服务 (
weclone-cli server) 正在运行。 - 打开一个新的命令行窗口 (并激活虚拟环境),然后运行:测试结果会输出到
1
weclone-cli test-model
test_result-my.txt。
部署到聊天机器人
通过 AstrBot 部署
通过 AstrBot 部署到聊天机器人操作流程
AstrBot 是一个支持多平台的 LLM 聊天机器人框架,可以将你的 WeClone 模型部署到 QQ、微信、Telegram 等平台。
部署 AstrBot: 根据 AstrBot 官方文档的指引,在你的服务器或本地安装并配置好 AstrBot。
启动 WeClone API 服务: 确保你的
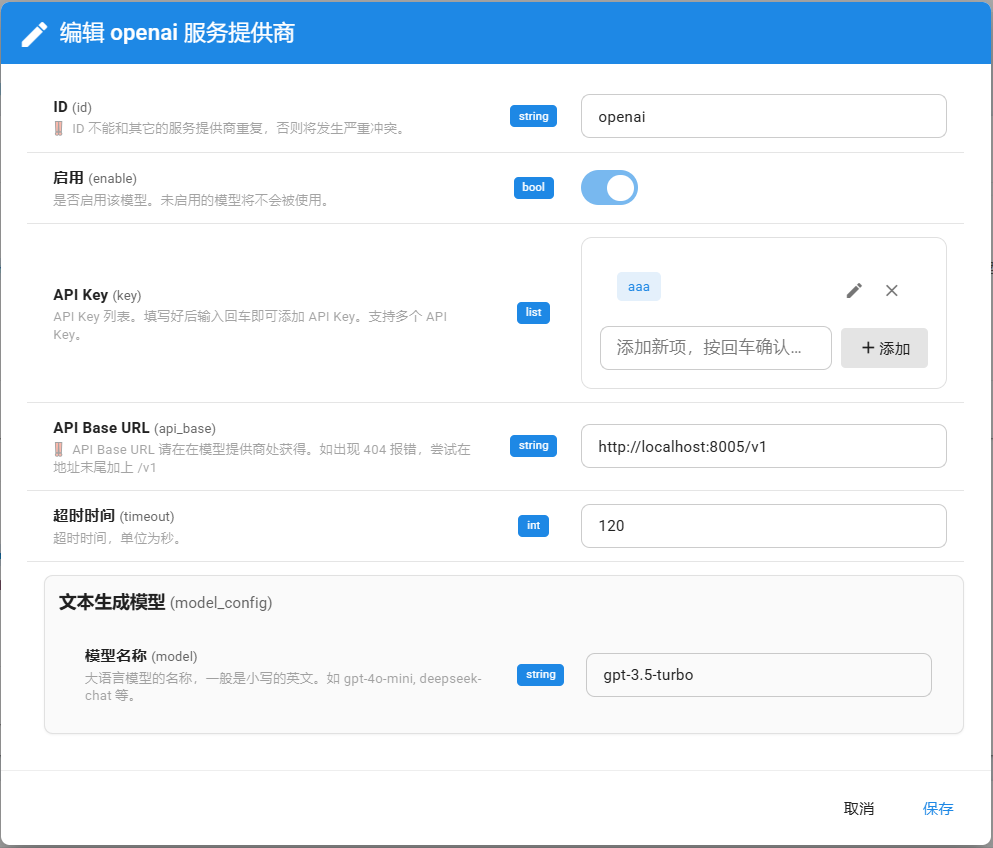
weclone-cli server正在运行,并且 AstrBot 可以访问到该服务的地址和端口 (例如,如果 AstrBot 和 API 服务在同一台机器上,可能是http://1ocalhost:8005/v1)。在 AstrBot 中新增服务提供商:
- 启动AstrBot ,并进入其web UI界面,一般是
http://localhost:6185。 - 依次点击服务提供商→新增服务提供商
- 类型选择:OpenAI
- API Base URL:填写你的 WeClone API 服务地址 (如果部署在本地则填写
http://localhost:8005/v1)。 - 模型:可以填写一个占位符,如
gpt-3.5-turbo(因为实际使用的模型由 WeClone API 服务决定)。 - API Key:随意填写一个即可(填写完记得回车或者点击右侧添加按钮)
- 完成后点击“启用”和“保存”等待AstrBot 重启。
- 启动AstrBot ,并进入其web UI界面,一般是
在 AstrBot 中部署消息平台: 在“消息平台”界面配置 AstrBot ,以连接到你希望使用的聊天平台 (如微信、QQ 等)。不同消息平台应参照 AstrBot官方文档 。例如如果你想要部署到QQ,可以参考下面AstrBot提供的教程:通过 NapCatQQ 协议实现端接入 QQ | AstrBot
关闭工具调用 (重要):
微调后的模型主要用于模仿你的语言风格,通常不支持复杂的工具调用。在 AstrBot 对应的聊天平台中,向你的机器人发送指令关闭所有默认工具,以确保能看到微调效果:1
/tool off all
你还可以在“插件管理”页面手动关闭系统插件。这里我只保留了
astrbot、session_controller两个系统插件。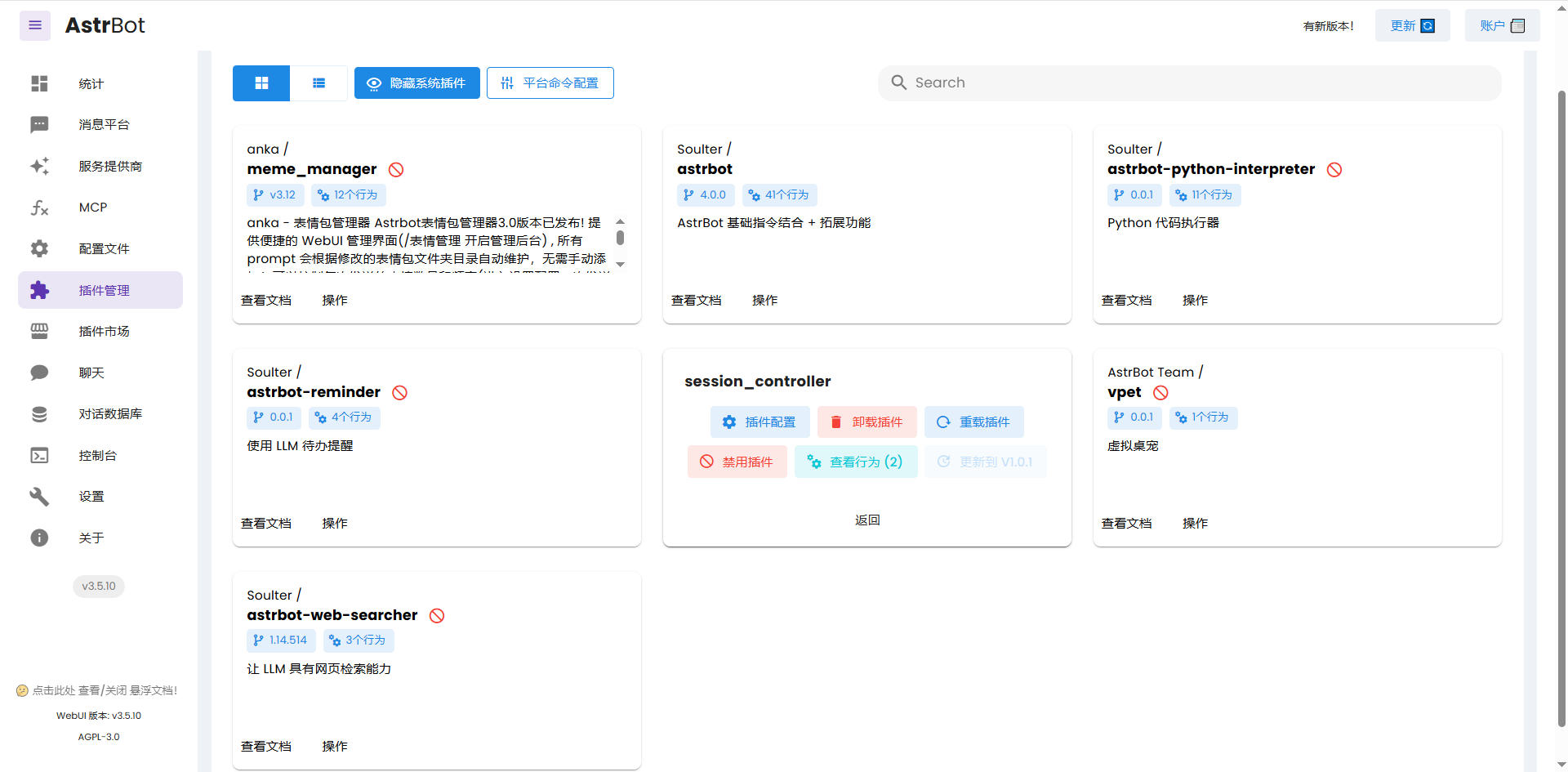
设置系统提示词:
在 AstrBot 的配置中,为你的机器人设置系统提示词 (System Prompt)。这个提示词必须与你微调模型时在settings.jsonc中设置的default_system完全一致。
其他功能
在“配置文件”界面还有其他很多配置,可以查询 AstrBot官方文档 自行调节。
调整采样参数:
根据你在浏览器 Demo 或其他测试中得到的最佳效果,在 AstrBot 中调整模型的采样参数,如temperature,top_p,top_k等。具体配置方法请参考 AstrBot 文档中关于配置自定义的模型参数 | AstrBot的部分。
⚠️
经常检查api_service.py的日志输出,确保 AstrBot 发送给大模型服务的请求参数 (如 system prompt, temperature 等) 与你微调和测试时期望的一致。
通过 LangBot 部署
通过 LangBot 部署到聊天机器人操作流程
LangBot 是一个开源的接入全球多种即时通信平台的 LLM 机器人平台,适合各种场景使用。将WeClone服务端接入LangBot的流程与接入AstrBot类似。下面是流程简介:
- 部署 LangBot
- 在 LangBot 中添加一个机器人
- 在模型页添加新模型,名称
gpt-3.5-turbo,供应商选择 OpenAI,填写 请求 URL 为 WeClone 的地址,详细连接方式可以参考文档,API Key 任意填写。
- 在流水线配置中选择刚才添加的模型,或修改提示词配置
通过 Dify 部署到工作流
点击展开:Dify 部署 WeClone 到工作流的操作流程
Dify 是一个开源的 LLM 应用开发平台,致力于帮助开发者快速构建生成式 AI 应用。它提供直观易用的界面,结合 AI 工作流、RAG 管道、代理功能与模型管理等特性,大幅简化了从原型构建到实际部署的流程。
你可以将 WeClone 中的模型部署到 Dify,并集成进你的工作流中,提升模型的可用性和交互能力。
以下是部署的基本流程:
- 部署 Dify:
可参考 Dify 官方文档 进行安装配置,或直接使用其提供的云服务。
配置模型供应商:
进入 Dify 主界面,点击左侧菜单中的 设置 → 模型供应商 → OpenAI → 添加模型。
按如下方式进行配置:- 模型名称:填写
gpt-3.5-turbo或其他 GPT 模型名称; - API Key / 组织 ID:可填写任意值;
- API Base:
- 若使用 Docker 部署的 Dify,请填写:
http://host.docker.internal:8005/ - 若使用 Dify 云服务,需要将本地服务暴露至公网,填写:
http://<公网IP地址>:8005/
⚠️ 出于安全考虑,不推荐直接将本地服务暴露至公网。
- 若使用 Docker 部署的 Dify,请填写:

- 模型名称:填写
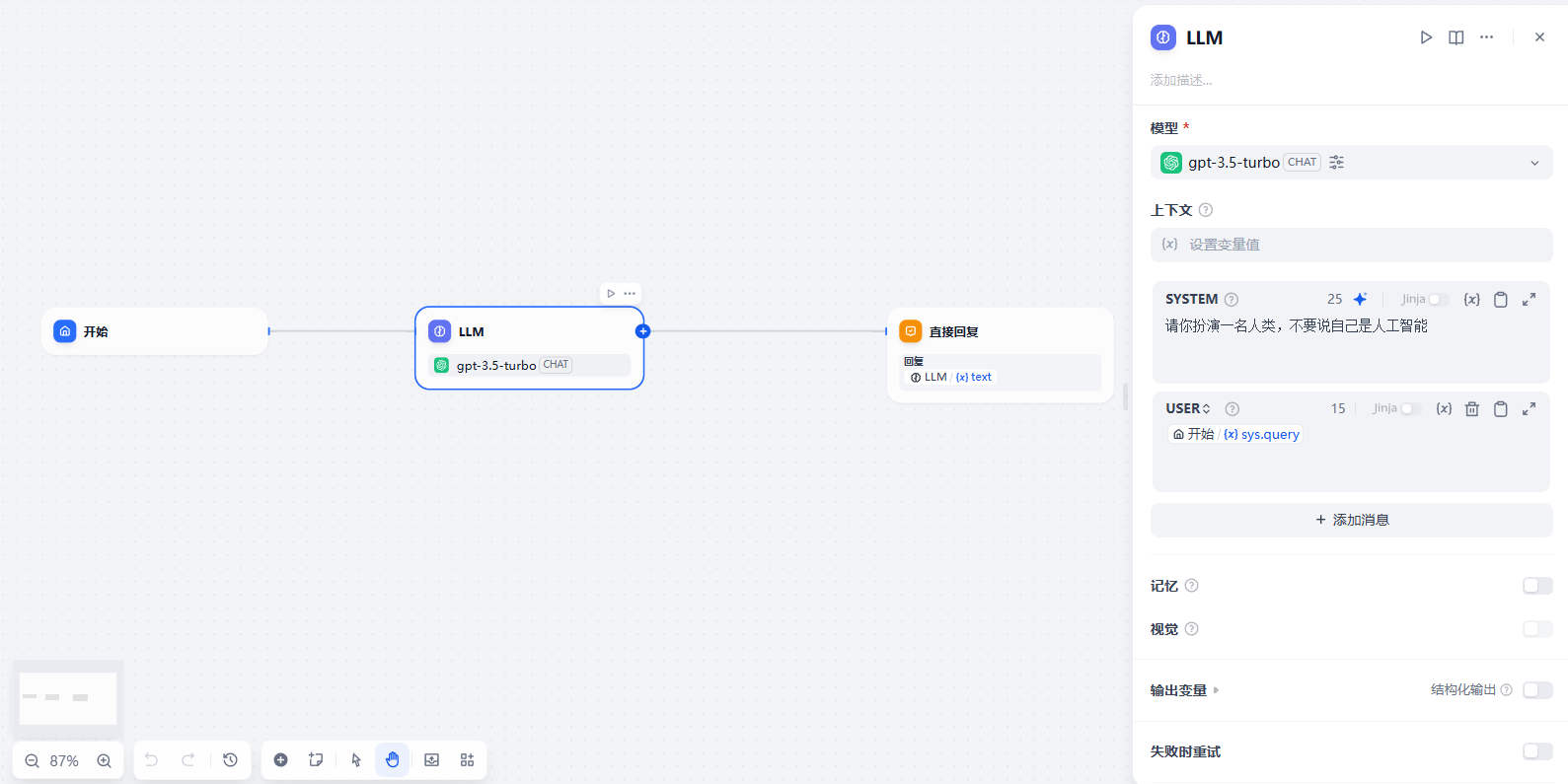
在工作流中插入 WeClone 模型节点
在 Dify 的工作流编辑器中,插入一个 LLM 节点,并将其绑定到刚才添加的模型(如
gpt-3.5-turbo)。
随后,在该节点的 System Prompt(SYSTEM) 配置中填写 WeClone 模型训练时所使用的提示词。
若你使用的是 WeClone 的默认配置,则应填入:1
请你扮演一名人类,不要说自己是人工智能。
这样,模型在工作流中就能保持一致的语气风格与角色设定。
现在,你的专属数字分身应该已经成功部署到聊天机器人平台了!快去和“它”聊聊天,看看效果如何吧。
问题解决与支持
微调问题: 可以参考 LLaMA Factory 的 FAQs | 常见问题,因为 WeClone 底层使用了 LLaMA Factory 的部分组件或类似逻辑。
项目 Issues: 查看 WeClone GitHub 仓库的 Issues 和 Discussions 是否有类似问题和解决方案。
- 项目官方群聊:
免责声明
⚠️ ⚠️ ⚠️
请勿用于非法用途,否则后果自负。
本教程仅供学习交流使用。任何违反法律法规、侵犯他人合法权益的行为,均与WeClone项目及笔者无关。严禁用于窃取他人隐私。
参考资料
- xming521/WeClone – 从聊天记录创造数字分身的一站式解决方案:项目主页,涵盖聊天记录处理、LoRA 微调、声音克隆等模块,本文主要基于项目README编写。
- Windows AI 模型部署与训练指北:浮游大佬撰写的对Weclone部署的避坑指南,本文在二编中参考了很多其中的内容。
其余引用链接已在正文中明确标注。




